
¿Qué es el Index Bloat?
El index bloat es un problema en SEO que ocurre cuando los motores de búsqueda indexan más páginas de las necesarias dentro de un sitio web. Este exceso de páginas puede afectar el rendimiento general del sitio y su posicionamiento en los resultados de búsqueda.
Cuando un sitio web tiene demasiadas páginas indexadas que no aportan valor, los motores de búsqueda pueden malgastar su presupuesto de rastreo en contenido irrelevante en lugar de enfocarse en las páginas más importantes.
Causas principales del Index Bloat

El index bloat puede originarse por diversas razones, muchas de ellas relacionadas con la estructura del sitio y la configuración de indexación. Algunas de las causas más comunes incluyen:
Páginas generadas dinámicamente
Una de las principales causas del index bloat son las páginas generadas dinámicamente mediante parámetros de URL.
En muchos sitios, especialmente los e-commerce o portales con filtros avanzados, se crean múltiples versiones de una misma página según las combinaciones de parámetros (por ejemplo, color, talla o precio).
Ejemplo:
/productos/zapatos?color=rojo
/productos/zapatos?color=rojo&talla=40
A ojos de Google, cada una de estas URLs puede parecer una página distinta, lo que multiplica innecesariamente el número de páginas indexadas.
Solución recomendada:
Usar la etiqueta canonical o configurar los parámetros en Google Search Console para evitar la indexación de URLs redundantes.
Contenido duplicado
El contenido duplicado es otra fuente común de index bloat. Cuando varias páginas contienen texto idéntico o muy similar, los motores de búsqueda pueden indexarlas todas, dificultando identificar cuál es la versión principal.
Ejemplos frecuentes:
- Versiones HTTP y HTTPS indexadas al mismo tiempo.
- Páginas con y sin “www”.
- Paginación o filtros mal gestionados que generan URLs repetidas.
Solución:
Implementar redirecciones 301, etiquetas rel=“canonical” y una correcta gestión de versiones del dominio.
Etiquetas y categorías en blogs
Los blogs y CMS (como WordPress) generan automáticamente páginas de etiquetas y categorías. Si no se controlan, estas páginas pueden multiplicarse sin aportar valor real, especialmente cuando agrupan pocas entradas o contienen contenido repetido.
Recomendación:
- Evitar que las páginas de etiquetas y categorías se indexen si no están optimizadas.
- Utilizar meta robots noindex o bloquearlas desde el archivo robots.txt.
Páginas de resultados de búsqueda interna
Permitir que Google indexe las páginas de resultados de búsqueda interna es un error común. Estas páginas no tienen valor para el usuario y solo generan duplicidad de contenido y URLs innecesarias.
Ejemplo:
/buscar?query=producto1
Solución:
Bloquearlas con noindex o mediante robots.txt, para que los motores no desperdicien recursos rastreándolas.
Páginas con poco o ningún contenido
Las páginas con contenido escaso o thin content también contribuyen al index bloat. Se trata de páginas sin información útil, de prueba o vacías que terminan siendo indexadas.
Ejemplo:
Páginas de error, formularios sin texto o fichas de productos sin descripción.
Solución:
Eliminarlas o combinarlas con otras páginas más completas y relevantes.
Versiones alternativas de una misma página
Algunos sitios generan versiones duplicadas de una página para distintos dispositivos (móviles, AMP o escritorio). Si no se gestionan correctamente, todas pueden indexarse como páginas independientes.
Solución:
Usar etiquetas canonical o hreflang (si aplica por idioma) para indicar la versión principal.
¿Cómo detectar el Index Bloat?
Identificar el index bloat en un sitio web es clave para mejorar el rendimiento SEO. Existen varias herramientas y métodos que pueden ayudar a detectar este problema.
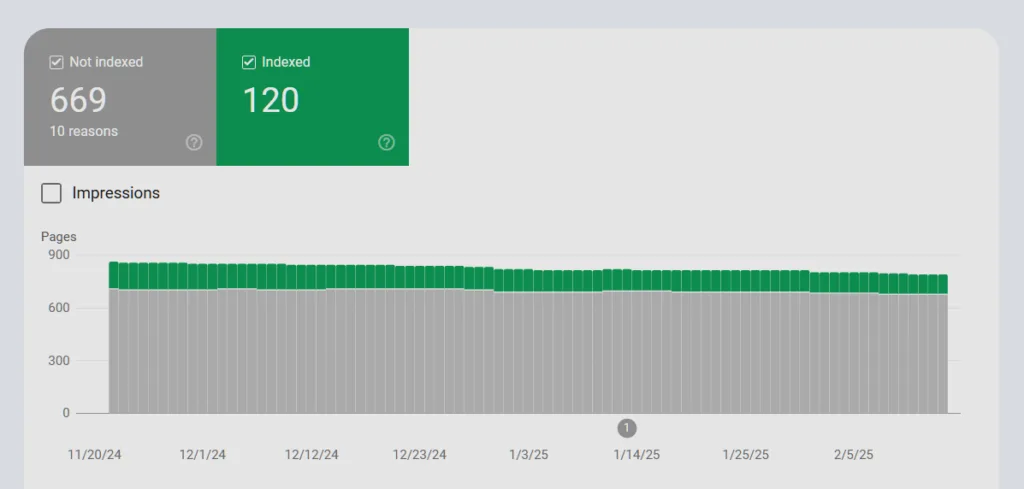
Uso de Google Search Console
Google Search Console permite revisar el número de páginas indexadas en la sección de Cobertura del índice. Si el número de páginas indexadas es mayor de lo esperado, puede ser una señal de index bloat.
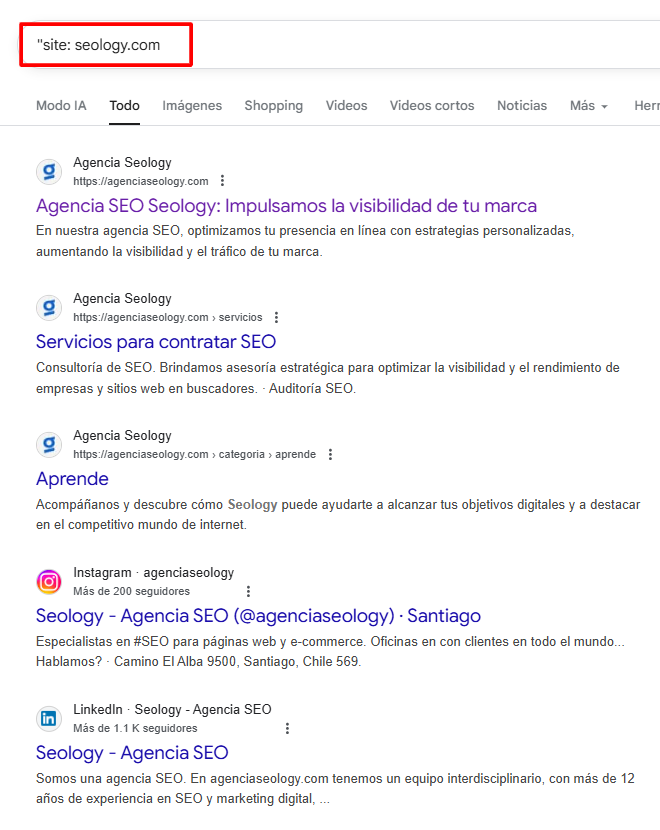
Comprobación con el operador Site:
Realizar una búsqueda en Google con el operador “site:tudominio.com” permite ver cuántas páginas están indexadas. Si el número de resultados es significativamente mayor que el número real de páginas importantes del sitio, es posible que haya index bloat.
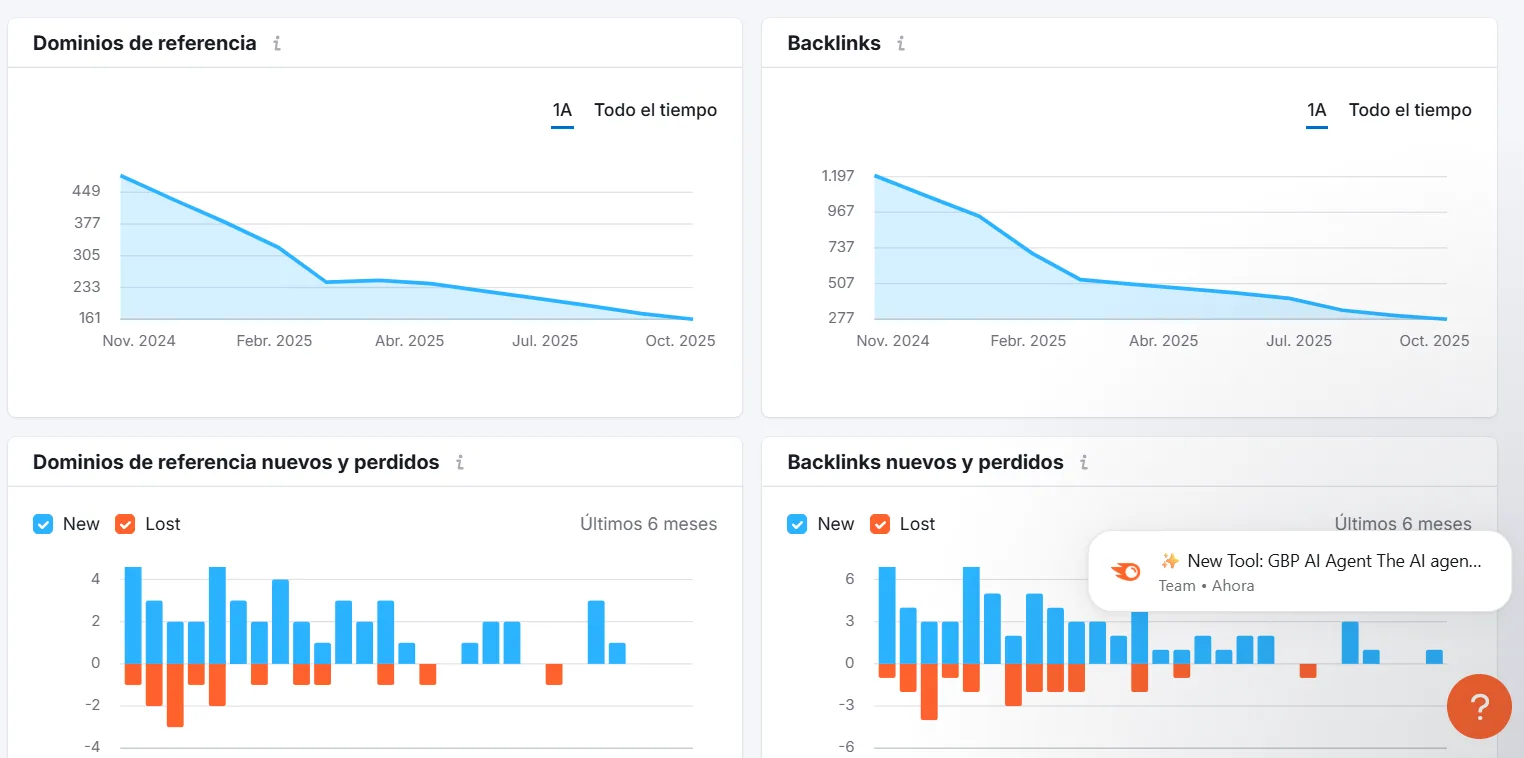
Análisis con herramientas de SEO
Herramientas como Ahrefs, Screaming Frog o Semrush permiten rastrear un sitio web y detectar páginas innecesarias en el índice. Estas herramientas ayudan a identificar contenido duplicado, páginas de bajo valor y problemas de indexación.
¿Cómo solucionar el Index Bloat?
Reducir el index bloat es fundamental para optimizar el presupuesto de rastreo y mejorar el posicionamiento en los motores de búsqueda. Existen varias estrategias para solucionar este problema.
1. Uso de la etiqueta Noindex
Una de las formas más directas para controlar qué páginas no deben aparecer en los resultados de búsqueda es implementar la etiqueta meta “noindex”. Esta instrucción le indica a Google que, aunque puede rastrear la página, no debe incluirla en su índice.
Cuándo usar “noindex”:
- En páginas de resultados internos (por ejemplo, /buscar?query=).
- En etiquetas o categorías sin contenido.
- En páginas de confirmación o agradecimiento (por ejemplo, /gracias-por-tu-compra).
- En páginas de login, políticas internas o archivos PDF sin valor SEO.
Ejemplo de código:
<meta name=”robots” content=”noindex, follow”>Este código permite que Google siga los enlaces de la página, pero no la indexe.
2. Gestión correcta del archivo robots.txt
El archivo robots.txt es una herramienta esencial para controlar el rastreo. Aunque no evita la indexación directa, sí puede bloquear el acceso de los bots a determinadas secciones, reduciendo el desperdicio del presupuesto de rastreo.
Ejemplo práctico:
User-agent: *
Disallow: /wp-admin/
Disallow: /buscar/
Disallow: /etiquetas/
Esto impide que Googlebot y otros rastreadores accedan a esas rutas, evitando que las páginas internas de baja relevancia se rastreen repetidamente.
Lleva tu estrategia SEO al siguiente nivel
Implementar estas estrategias de forma efectiva marca la diferencia entre el éxito y el estancamiento digital. Si necesitas apoyo profesional, en Seology tenemos presencia en mercados clave: nuestra agencia SEO Colombia atiende empresas que buscan crecer en el mercado colombiano, y nuestra Agencia SEO en Chile impulsa la visibilidad de negocios en el mercado chileno.
Recomendación:
Usar este método solo para páginas que no necesitan ser rastreadas en absoluto, pero que tampoco deben mostrarse en los resultados. Para páginas públicas, es mejor usar la etiqueta noindex.
3. Implementación de canonical tags
Las etiquetas canonical ayudan a los motores de búsqueda a identificar cuál es la versión principal de una página cuando existen varias con contenido similar. Esto evita que las versiones duplicadas o parametrizadas compitan entre sí.
Ejemplo:
<link rel=”canonical” href=”https://www.ejemplo.com/producto-zapatillas/”>Cuándo usar etiquetas canonical:
- En páginas con parámetros de URL (?color=rojo, ?talla=40).
- En versiones de contenido duplicadas o con pequeñas variaciones.
- En páginas de paginación, cuando es necesario indicar la principal.
El uso correcto de canonicals consolida la autoridad SEO y evita que Google indexe múltiples versiones del mismo contenido.
4. Eliminación de páginas innecesarias
Una medida más drástica, pero efectiva, es eliminar definitivamente las páginas que no aportan valor. Esto ayuda a mantener el sitio más limpio, coherente y optimizado.
Ejemplos de páginas que se pueden eliminar:
- Contenido duplicado o desactualizado.
- Páginas de prueba o temporales.
- Entradas del blog vacías o con poco texto.
- URLs generadas automáticamente por sistemas CMS.
Tras eliminar una página, es importante:
- Implementar un código 410 (Gone) o 301 (Redirección permanente) si existe una versión relevante.
- Actualizar los enlaces internos para evitar errores 404.
- Solicitar una reindexación en Google Search Console para limpiar el índice.
5. Optimización de la estructura del sitio
Una estructura clara y bien planificada evita la creación excesiva de páginas. Optimizar la arquitectura web contribuye a reducir el Index Bloat desde su raíz.
Buenas prácticas:
- Evitar que los sistemas de etiquetas o categorías generen miles de URLs sin contenido.
- Controlar los parámetros dinámicos mediante Google Search Console o reglas en el CMS.
- Utilizar una jerarquía lógica con enlaces internos bien distribuidos.
- Consolidar versiones similares de una misma página (por ejemplo, contenido de productos casi idénticos).
- Revisar la paginación para no duplicar contenido o crear URLs huérfanas.
Una estructura eficiente facilita el rastreo de las páginas importantes y mejora la experiencia del usuario.
¿Cómo eliminar URL del índice de Google?
Eliminar URL innecesarias del índice de Google es una acción clave para mantener la salud SEO de un sitio web. Un índice limpio y optimizado mejora la eficiencia del rastreo, evita el index bloat y asegura que solo las páginas relevantes aparezcan en los resultados de búsqueda.
¿Por qué eliminar URL del índice de Google?
Cuando Google indexa páginas que no aportan valor -como versiones duplicadas, URLs temporales o páginas sin contenido- el sitio puede verse afectado negativamente. Estas páginas:
- Diluyen la autoridad del dominio.
- Consumen el presupuesto de rastreo.
- Afectan la visibilidad de las páginas realmente importantes.
Eliminar las URLs innecesarias permite que Google se centre en el contenido que realmente importa para el posicionamiento.
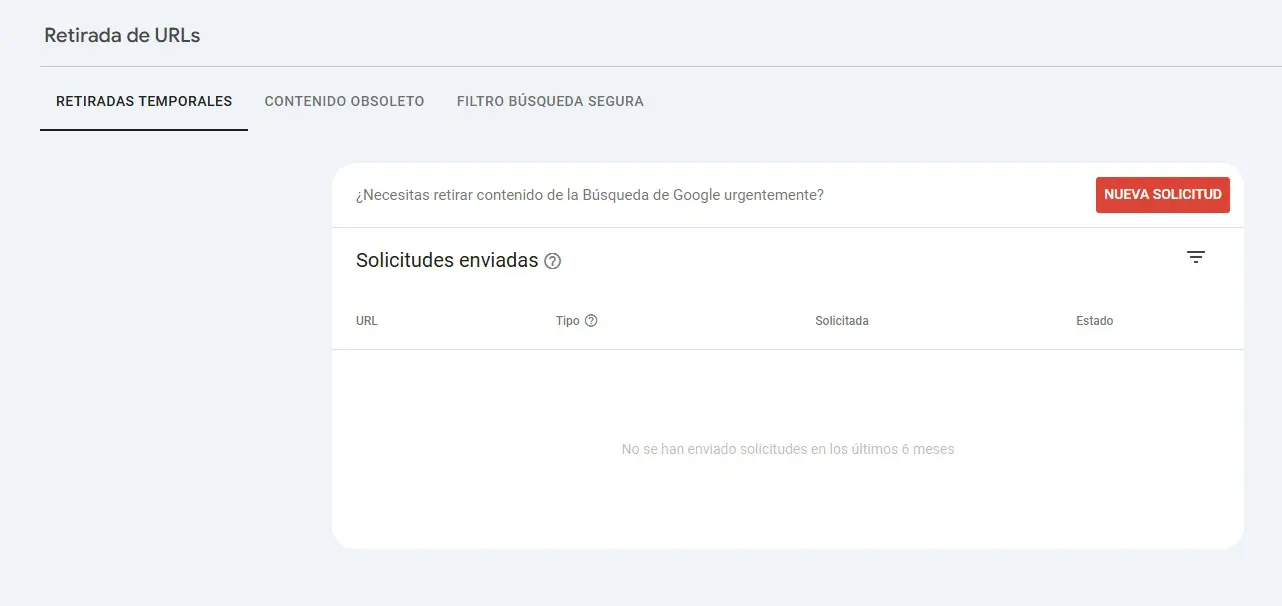
Eliminar URLs desde Google Search Console
La herramienta de eliminación de URL de Google Search Console es el método más directo para desindexar páginas. Para hacerlo:
- Accede a Search Console.
- En el menú lateral, selecciona “Remociones”.
- Haz clic en “Nueva solicitud”.
- Ingresa la URL que deseas eliminar.
Google la eliminará temporalmente de los resultados, normalmente por unos 6 meses, aunque la página puede volver a indexarse si sigue siendo accesible.
Uso de la etiqueta “noindex”
Para eliminar una página del índice de manera permanente, debes añadir una metaetiqueta “noindex” en el código HTML:
<meta name=”robots” content=”noindex, follow”>Esta instrucción indica a Google que no debe indexar la página, pero sí puede seguir los enlaces que contiene.
Después de implementarla, es necesario permitir que Google rastree la página (no bloquearla con robots.txt) para que detecte la instrucción “noindex”.
Bloquear URLs mediante el archivo Robots.txt
El archivo robots.txt ayuda a evitar que los rastreadores accedan a determinadas secciones del sitio. Sin embargo, no elimina páginas ya indexadas.
Por eso, debe usarse solo como medida preventiva. Un ejemplo sería:
User-agent: *
Disallow: /busqueda/
Esto impide el rastreo de URLs que contengan “/busqueda/”, pero si ya están en el índice, deberás combinarlas con la etiqueta noindex o una solicitud de eliminación.
Redirección 301 a páginas relevantes
Si una URL ha sido eliminada, pero recibía tráfico o enlaces entrantes, lo ideal es aplicar una redirección 301 hacia una página similar o de mayor valor.
Esto:
- Transfiere parte de la autoridad SEO.
- Mejora la experiencia del usuario.
- Evita errores 404 innecesarios.
Eliminación mediante código de estado 404 o 410
Si una página ya no existe y no tiene sustituto, se recomienda devolver un código de estado 404 (no encontrado) o 410 (eliminado).
Google detectará estos códigos durante el rastreo y eliminará las páginas del índice en un plazo de días o semanas.
¿Por qué es importante solucionar el exceso de indexación?

Este problema es más común de lo que parece y puede afectar seriamente el rendimiento SEO. Mantener un índice optimizado es fundamental para asegurar que Google rastree e interprete correctamente el contenido relevante de un sitio.
Mejora la eficiencia del presupuesto de rastreo
Google asigna a cada sitio un presupuesto de rastreo, es decir, la cantidad de URLs que el robot puede visitar e indexar en un período determinado. Cuando hay cientos de páginas irrelevantes indexadas -como versiones duplicadas, URLs con parámetros o páginas vacías- el rastreador desperdicia tiempo y recursos en ellas, dejando de lado las páginas más importantes.
Al eliminar el exceso de indexación, se optimiza este presupuesto y se garantiza que Google enfoque sus recursos en el contenido que realmente aporta valor.
Aumenta la visibilidad de las páginas relevantes
Un sitio saturado de URLs inútiles puede diluir la autoridad interna y reducir la visibilidad de las páginas más estratégicas. Por ejemplo, si un sitio tiene miles de páginas de etiquetas o resultados de búsqueda interna indexadas, estas competirán con las páginas de productos, servicios o artículos clave.
Al solucionar el exceso de indexación, se mejora la distribución del link juice y se refuerza el posicionamiento de las URLs prioritarias.
Mejora la experiencia del usuario
El exceso de páginas indexadas también puede perjudicar la experiencia del usuario. Si Google muestra en los resultados páginas vacías, duplicadas o irrelevantes, el visitante puede abandonar el sitio rápidamente, aumentando la tasa de rebote y afectando la reputación del dominio.
Mantener solo las páginas útiles en el índice garantiza que los usuarios encuentren contenido de calidad y relevante.
Contribuye a un sitio más ordenado y fácil de gestionar
Reducir el exceso de indexación no solo mejora el SEO, sino también la gestión interna del sitio web. Permite identificar contenido duplicado, enlaces rotos y páginas obsoletas, contribuyendo a una estructura más limpia y coherente. Esto facilita futuras optimizaciones, auditorías y estrategias de contenido.
Reducir el index bloat es clave para mejorar el rendimiento SEO de un sitio web. Si quieres aprender más sobre estrategias de SEO y marketing digital, sigue explorando los artículos de mi blog.
Encuentra en Seology estrategias SEO para Empresas de Software, E Commerce, Universidades y cualquier otra industria.



